Работа с выборкой
На данной странице под «работой с выборкой» понимается «работа со строками» файла выборки, загруженного в Проект на Платформе.
В платформе ANTAVIRA доступен следующий функционал при работе с выборкой:
- Формирование выборки;
- Деление выборки.
Формирование выборки
При необходимости ограничения/фильтрации выборки для моделирования по каким-либо условиям Вы можете использовать:
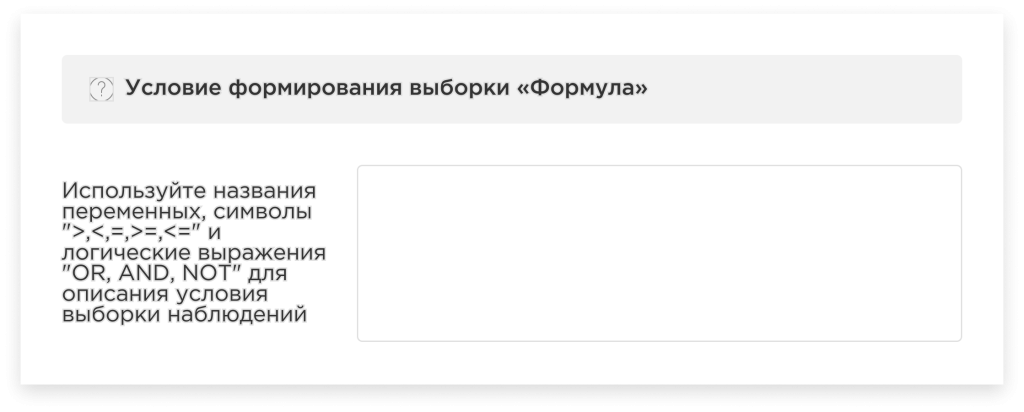
Условие формирования выборки «Формула»:
В данном случае Вам необходимо написать формулу для логического выражения условия. Формула формируется при помощи переменных. Тогда в моделировании будут участвовать только те наблюдения, которые соответствуют заданной формуле. Другими словами, платформа будет осуществлять фильтрацию строк всего датасета по заданному Вами условию.
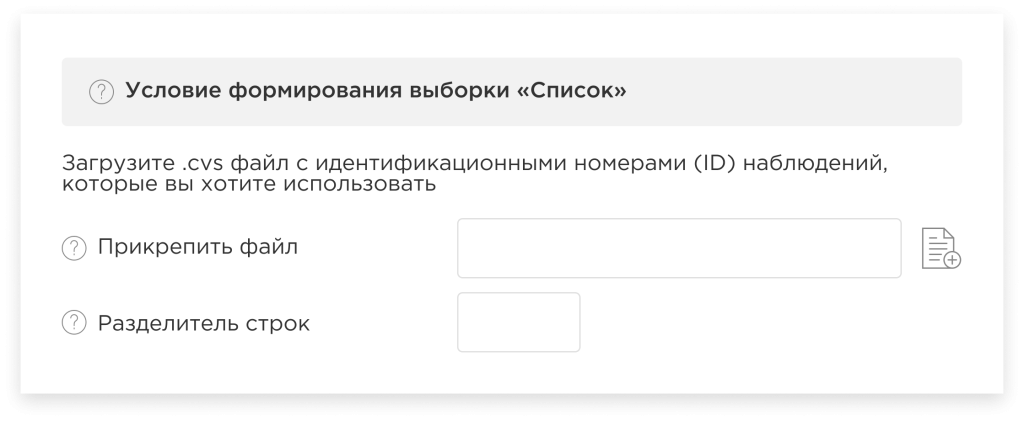
Условие формирования выборки «Список» (в разработке):
В данном случае, напротив, Вам необходимо загрузить CSV файл с идентификационными номерами наблюдений (строк), которые будут использоваться, и обозначить разделитель строк. Тогда в моделировании будут участвовать только те наблюдения (строки), которые соответствуют загруженному списку.
Если условия не заданы, то моделирование будет вестись по всей выборке.
Деление выборки
Одновременно с ограничением выборки по какому-либо условию в платформе ANTAVIRA доступен функционал деления выборки на обучающую и тестовую. Соответственно, при работе с выборкой деление реализуется следующими способами, подлежащими гибкой настройке:
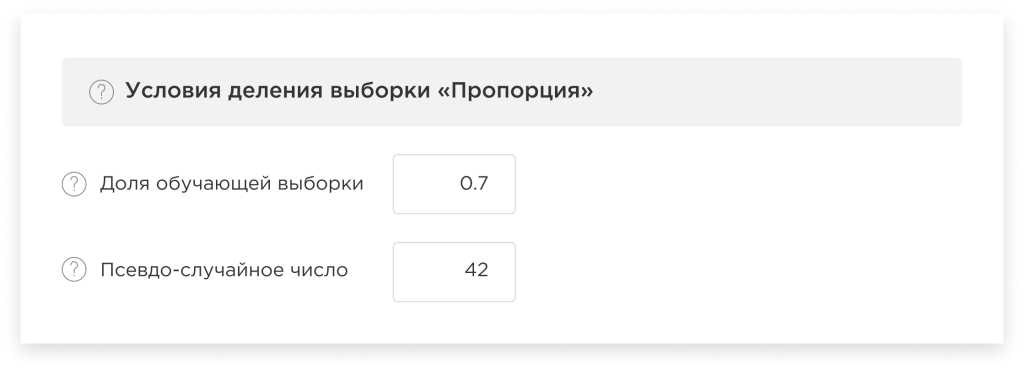
Деление выборки способом «Пропорция»:
В данном случае Вы можете задать долю обучающей выборки самостоятельно, а остальная часть будет использоваться платформой в качестве тестовой.
При этом, если на предыдущем шаге при формировании графа Вы указали последовательное использование двух делителей выборки, то результаты первого деления будут являться входными данными для второго деления. Таким образом, Вы получите одну обучающую и две тестовые выборки, использование которых может улучшить надежность и обобщающую способность модели, позволяя более точно оценить ее производительность и обнаружить возможные проблемы, а также поможет убедиться, что результаты стабильны и не зависят от конкретной выборки.
Кроме того, Вы можете задать самостоятельно псевдо-случайное число для того, чтобы получить случайное и сбалансированное разделение данных на обучающую и тестовую выборки, а также устранить возможные искажения, связанные с предвзятостью в данных.
Деление выборки способом «Пропорция с сортировкой»
Функционал находится в доработке.
Деление выборки способом «Время и/или дата»
Функционал находится в доработке.
Деление выборки способом «На равные части»:
Функционал находится в доработке.