Работа с переменными
На данной странице под «работой с переменными» понимается «работа со столбцами», загруженного файла с переменными в Проект.
В платформе ANTAVIRA доступен следующий функционал при работе с переменными:
- Формирование списка переменных;
- Обработка значений переменных;
- Измерение корреляции переменных.
Формирование списка переменных
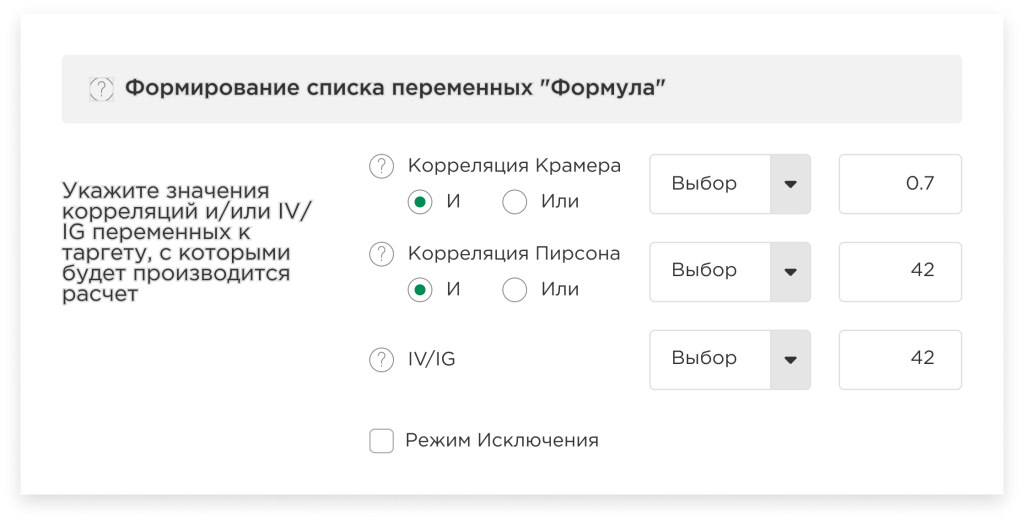
Формирование списка переменных «Формула» (В разработке):
В данном случае Вам необходимо указать значения корреляций (Крамера и/или Пирсона) и/или IV/IG переменных по отношению к значению таргетов, с которыми будет производиться расчет, для того чтобы платформа могла вычистить переменные, низко коррелирующие с таргетом. Тогда в моделировании будут участвовать только те переменные, которые соответствуют заданной формуле. Другими словами, платформа будет осуществлять фильтрацию столбцов всего датасета по заданному Вами условию.
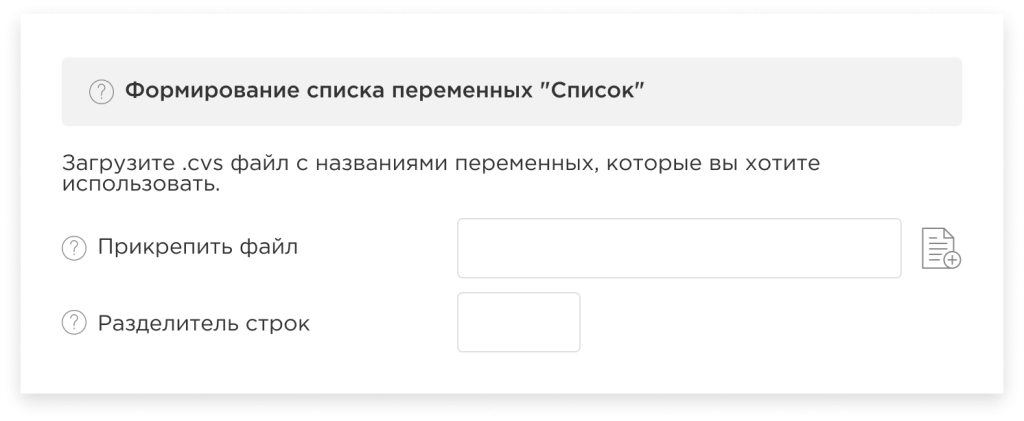
Формирование списка переменных «Список»:
В данном случае, напротив, Вам необходимо загрузить CSV файл с названиями переменных (столбцов), которые будут использоваться, и обозначить разделитель строк. Тогда в моделировании будут участвовать только те переменные (столбцы), которые соответствуют загруженному списку.
Если условия не заданы, то моделирование будет вестись по всей выборке.
Обработка значений переменных
ANTAVIRA позволяет обрабатывать значения переменных 5 разными способами:
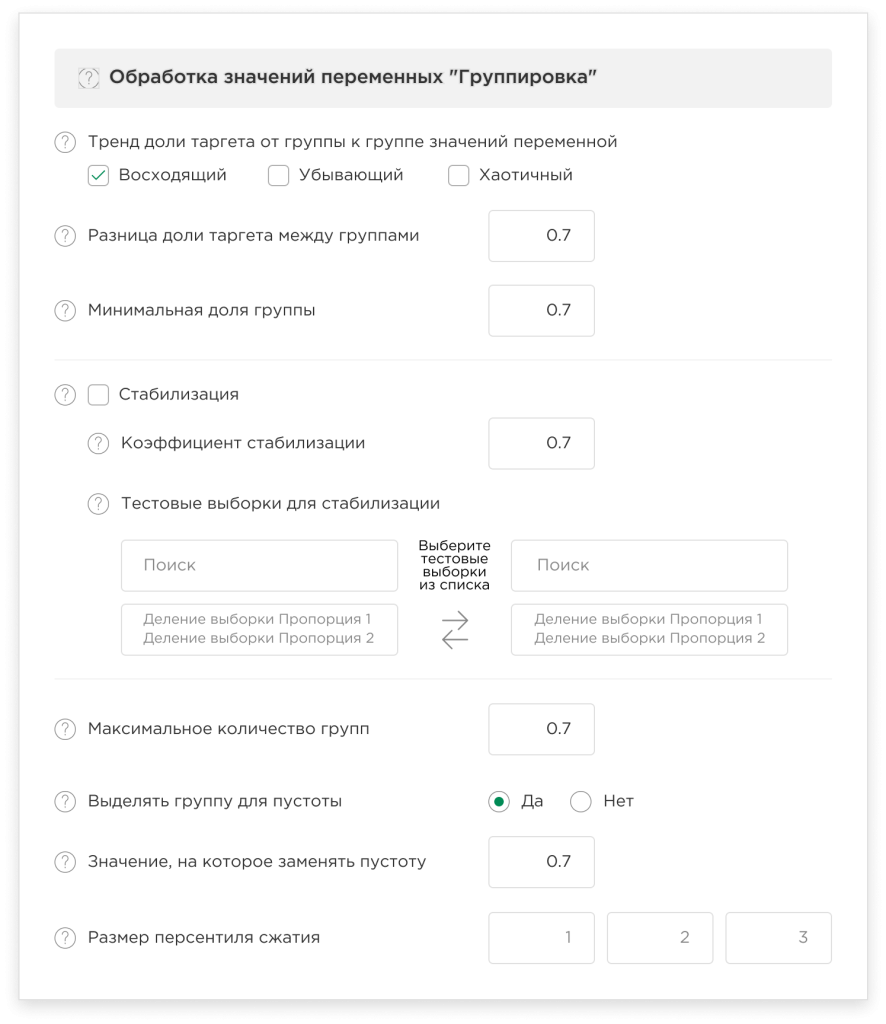
Группировка
Гибкая настройка данного модуля позволяет:
- Создать несколько наборов настроек с различными параметрами анализа для группирования:
Вы можете экспериментировать с различными наборами настроек для «Grid search», чтобы найти наилучший вариант группировки переменных.
Настраиваемыми параметрами являются:
- Тренд доли таргета от группы к группе значений переменных (восходящий, убывающий, хаотичный). В таком случае после проведения группирования платформа оставит только те переменные, которые подчиняются выбранным трендам.
- Разница доли таргета между группами. Это минимальное значение, на которое по Вашему мнению, должна различаться доля таргета соседних групп. Чем больше разница между долями таргетов соседних групп, тем выше предсказательная сила.
- Минимальная доля группы. Это минимальный размер наблюдений с таргетами, который входит в группу. Мы рекомендуем выбирать минимальную долю таким образом, чтобы количество наблюдений, попавших в минимальную группу, было статистически значимым числом (мы считаем статистически значимым числом либо не менее 5% от выборки и не менее 150 наблюдений).
- Стабилизация. Это собственная разработка, которая позволяет отобрать стабильные переменные как на обучающей, так и на тестовой выборке. То есть тренд, доля групп и значения доли таргетов будут соответствовать на тестовой и на обучающей выборке согласно указанному коэффициенту.
Например, коэффициент стабилизации 0,75; переменная v1; группа 1; обучающая выборка – доля группы 20%; доля таргета 60%; соответственно допустимые значения на тестовой выборке для данной группы – доля группы 15-25%; а доля таргета – 45-75%. Другими словами, отклонение от значений доли группы и доли таргета от обучающей выборки к тестовой выборке должно составить не более 25%. Т. е. данная функция позволяет отобрать переменные, которые одинаково работают на обучающей и тестовой выборке.
Также платформа позволяет выбрать одну или несколько тестовых выборок (в случае если Вы запускали делитель несколько раз) для стабилизации. Если Вы выбрали несколько тестовых выборок, то условие коэффициента стабилизации должно быть выполнено на всех выбранных выборках.
- Настроить количество групп.
Вы можете настроить максимальное количество групп, на которое модуль группирования должен разделить Ваш набор данных. Обратите внимание, что чем большее количество групп Вы указываете, тем больше времени занимает выполнение расчета, а количество групп не может превышать количества переменных. - Настроить обработку пустоты в Вашем датасете.
В целях избежания ошибок и искажений из-за пустот в процессе обучения модели Вы можете выделить группу для пустоты, чтобы исключить использование пропущенных значений при выполнении процесса группировки, а также Вам необходимо ввести значение, на которое заменять пустоту.
Если Вы уже самостоятельно заменили пустоты на какое-то значение, укажите данное значение. - Настроить размер персентиля сжатия.
Данная функция представляет собой предварительную процедуру сглаживания данных для ускорения процесса моделирования.
Настраивается в процентах. Обратите внимание, что чем меньше Вы поставите процент, тем детальнее будет происходить группировка и тем дольше времени она будет вестись.
Кластеризация
С целью объединения наблюдений на основе их схожих характеристик/переменных и взаимосвязи между ними в платформе также реализована кластеризация.
При настройке данного метода Вы можете самостоятельно указывать количество необходимых Вам кластеров. Обратите внимание, что чем большее количество кластеров Вы указываете, тем больше времени занимает выполнение расчета, а количество кластеров не может превышать количества переменных.
Бинирование
С целью снижения влияния шума и обработки выбросов, а также для снижения сложности модели за счет упрощения представления данных Вы можете использовать бинирование. При выполнении данного метода значения переменных разбиваются на диапазоны, называемые «бинами».
Таким образом, при работе в платформе Вам необходимо задать размер бина в процентном соотношении от обучающей выборки Вашего проекта.

Стандартизация
Представляет собой простейший метод обработки значений переменных в платформе в процессе подготовки и предобработки для построения моделей машинного обучения. Выполняется с целью преобразования значений переменных таким образом, чтобы обеспечить их сопоставимость в контексте моделирования.
Данный метод не подлежит гибкой настройке пользователем. При выборе его в графе платформа сама осуществит необходимые действия для выполнения стандартизации переменных.
Нормализация
Представляет собой простейший метод обработки значений переменных в платформе в процессе подготовки и предобработки для построения моделей машинного обучения. Выполняется с целью масштабирования значений переменных в пределах определенного диапазона и обеспечения их сопоставимости в контексте моделирования.
Данный метод не подлежит гибкой настройке пользователем. При выборе его в графе платформа сама осуществит необходимые действия для выполнения нормализации переменных.
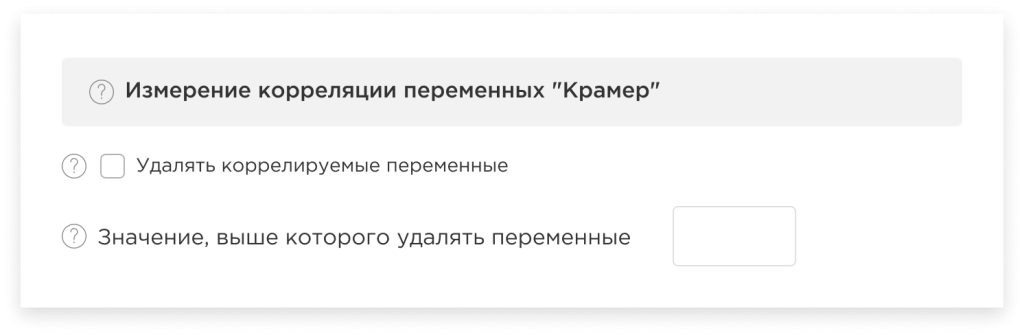
Измерение корреляции переменных
Для оптимизации модели путем исключения высоко коррелирующих переменных, как следствие, позволяющей сократить размерность данных и улучшить производительность модели, в платформе реализован функционал измерения коэффициента корреляции между переменными.
Способ корреляции зависит от выбранного Вами способа обработки значений переменных. Таким образом, Вы можете использовать:
Корреляцию Крамера
(в случае выбора группировки, кластеризации или бинирования).
Корреляцию Пирсона
(в случае выбора нормализации или стандартизации).
Кроме того, при необходимости Вы можете персонально настраивать значение корреляции, выше которого удалять переменные.