


Неотъемлемой частью построения качественной прогнозной модели являются шаги по обработке значений переменных. Они могут быть направлены на сглаживание и обработку выбросов или уменьшение дисперсиизначений переменных.
АНТАВИРА предлагает пользователям уникальную методику обработки значений переменных, нацеленную на повышение качества моделирования. В рамках нашей платформы данный процесс реализуется при помощи функции группировки данных выборки. Однако мы также планируем реализовать четыре общепринятых метода (кластеризация, бинирование, нормализация, стандартизация), поскольку многие математики начинают построение прогнозных моделей именно с них.
Группировка в АНТАВИРЕ, основанная на уникальной собственно разработанной методологии группировки переменных, схожа с нормализацией данных, однако обладает рядом существенных отличий и преимуществ в области прогнозного моделирования. Данная функция позволяет заменить значения переменной на номер группы, в которую попадает это значение, после разбиения выборки на группы в разрезе выбранной переменной по заданным параметрам. Настраиваемыми параметрами являются размер «персентиля» сжатия; числовое значение, на которое заменять пустоту; возможность выделения группы для пустоты; количество групп; разница доли таргета соседних групп; распределение доли таргета; минимально допустимый размер группы; стабилизация; коэффициент стабилизации.
Рассмотрим влияние настройки параметра «Разница доли таргета соседних групп» на качество моделирования при группировке переменных при всех других одинаковых настройках. Под данным параметром понимается минимальное значение, на которое, по мнению пользователя, должна различаться доля таргета соседних групп.
В начале эксперимента мы сделали предположение, что WOE у переменных будет выше там, где больше разница доли таргета соседних групп, следовательно, и модель будет лучше.
Запустим расчет с разницей в 10% (ML1) и 5% (ML2) доли таргета соседних групп:
| ML1 10% | ML2 5% |
 |
 |
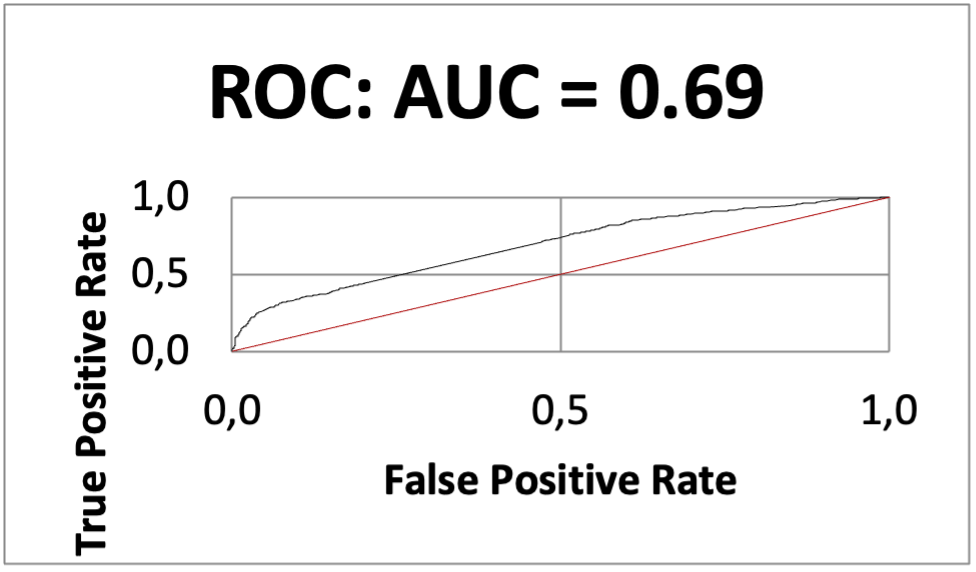
Получили следующие результаты:
| ML1 10% | ML2 5% |
 |
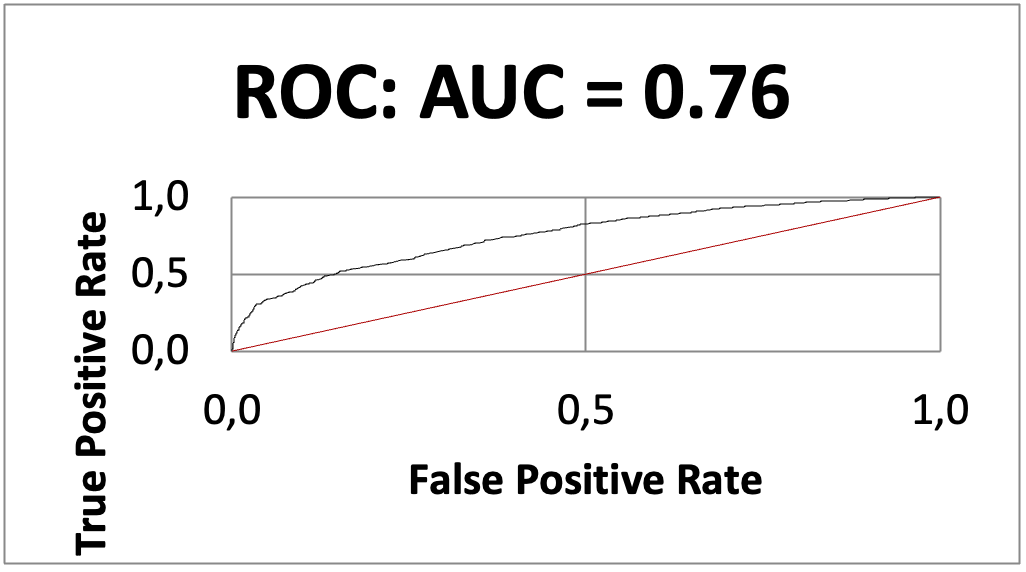 |
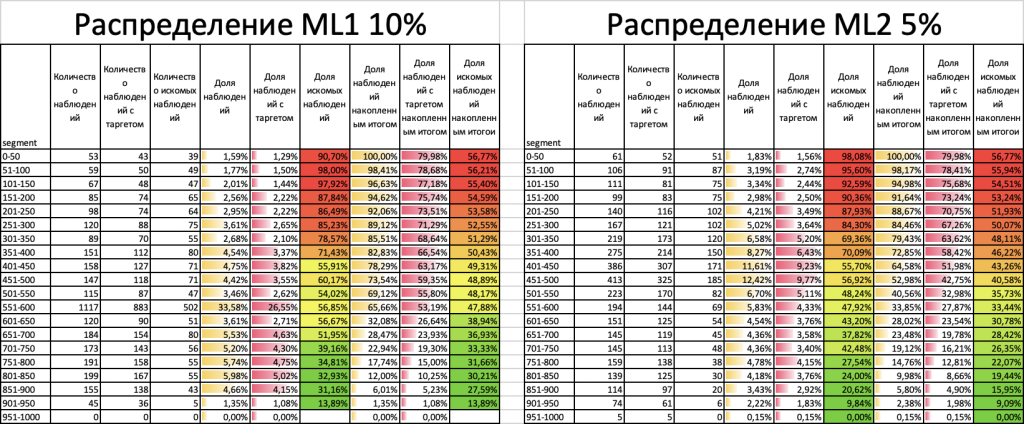



К сожалению, наша гипотеза не оправдалась. При группировке переменных модуль работает на достижение максимального IV, поэтому большинство переменных были сгруппированы одинаково и отобраны только в конце процесса по нужным параметрам разницы доли таргета соседних групп. Для ML1 осталось 28 переменных, для ML2 47 переменных. В результате ML2 получилась намного лучше ML1.
Тогда мы перешли к новой стратегии и поставили расчет с разницей доли таргета соседних групп в 3%. Результат не оправдал себя, так как получился подобным ML2, зато время расчета увеличилось очень значительно.
Согласно нашему опыту, оптимальный выбор настройки параметра «разница доли таргета соседних групп» при группировке значений переменных – это 5% от доли таргета во всей выборке. В нашем примере это настройка 5%, так как доля таргета – 57% во всей выборке.


